Table of Contents
Introduction to The Cluster
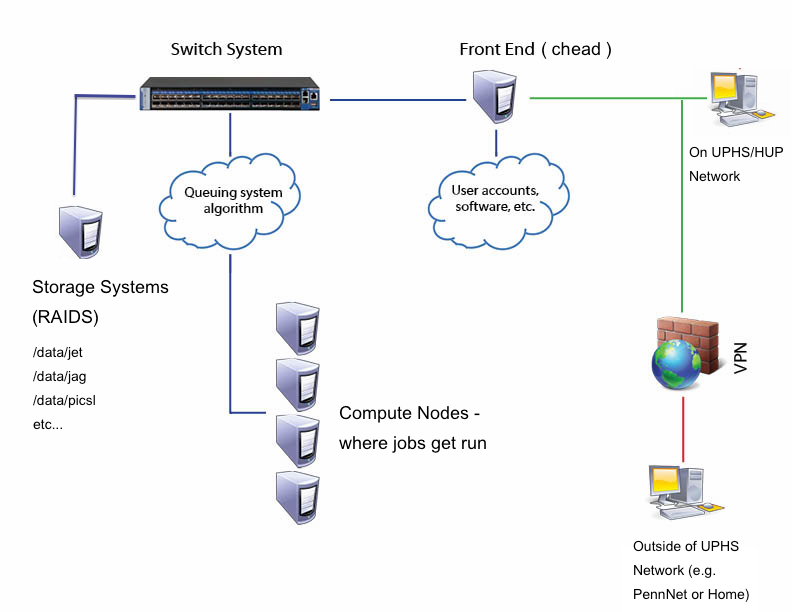
The cluster is a collection of servers that work together to provide flexible, high-volume computing resources to all researchers at CfN. All these servers are physically housed together in a server room, and are dedicated to running computing jobs. This differs from the old CfN cluster, in which many of the servers were desktop machines in various labs. This meant that your desktop machine might slow down as the old cluster used it. We don't have that problem now with this new cluster.
The cluster has a single login server, called the front end or head node. To use the cluster you login to the front end (chead.uphs.upenn.edu in our case) using your CfN account. You then use a job scheduler (SGE) to either:
- a) ask for an interactive login session to run something like the Matlab GUI, or use a terminal interactively - i.e. to type commands and run things that way.
- b) submit your jobs in batch mode - a job is basically any script that you want to run; e.g. linux shell, python, perl, etc., or sometimes just a command. This is the most common use.
We'll discuss these methods in detail later in the wiki.
In either case, the job scheduler takes care of finding a compute node to do the actual work of running your batch job or interactive session (both are called 'jobs' by the scheduler, actually).
The cluster is running CentOS 6.9 (Linux operating system version) with Rocks 6.2 (Cluster management system). This is the software that manages the collection of front and compute nodes, i.e. the cluster - Rocks is not the job scheduler. The jobs scheduler is SGE (Actually SoGE, Son of Grid Engine, see below).
General Cluster Diagram
The Queue - running multiple jobs
The great thing about the cluster is that you can submit a lot of jobs at once (thousands, even), and walk away while they all run. By default, up to 32 of them will run at once if there's enough space on the cluster. The rest will stay in the job queue, a list of all the jobs submitted by all the users. When one of your jobs finishes, the scheduler will search the queue for any jobs of yours that are waiting, and start them up if found.
NOTE the 32-job limit is actually a 32-slot limit. If you're multi-threading your jobs, you'll be able to run fewer of them at once. See the discussion further on in this wiki for details.
If the cluster is busy, the scheduler may run fewer than 32 of your jobs at once, making sure every user gets their queued jobs run in turn.
NOTE Before you submit a whole pile of jobs, e.g. to do the same processing on a large collection of patient data, be sure to test your job on just a single patient or subset of the data.
Don't (generally) run programs on the front end itself
Note that generally no jobs or apps should be run on the front end (i.e. chead) directly. Always use the job scheduler to submit your jobs (see below).
EXCEPTIONS
Low-intensity tasks and jobs
If you're running something quick like using fslview or ITK-SNAP to look at an image and do simple manipulations, then it's ok to use the front end instead of an interactive job. This actually makes for more efficient use of the compute nodes since you won't be tying up a qlogin session when you're not really use much computational power. Just don't forget to exit your app when you're done. The important thing is not to run computationally intensive jobs on the front end, like using Matlab to run an analysis on some data.
Limits and TERMINATION
Applications/jobs/processes that use more than 5GB RAM or 5 minutes of CPU time on the front end will be unceremoniously terminated. You will see a message like CPU time limit exceeded.This means five minutes of the CPU's time, not five minutes of real world time or “wall clock time”. So viewing images or testing matlab scripts that don't do lots of computation will run for much longer than five minutes, pretty much indefinitely. If you really need to run something for longer on the front end, let me know - there's a way to increase the Memory and CPU limits case-by-case. But normally you should run things using qlogin or qsub - see the section below on the Job Scheduler (SGE).
The Job Scheduler - SGE
The job scheduler is an open-source version of the standard Sun Grid Engine (which was recently made closed-source). Its name is Son of Grid Engine (SoGE, version 8.1.8). Its website: https://arc.liv.ac.uk/trac/SGE Generally we'll call this SGE.
If you're familiar with the PICSL cluster, our version of SGE is very similar, give or take just a little. The main commands for users are still qlogin, qsub, etc. We'll discuss these in detail later in the wiki (Using SGE), but please first keep reading below.
Applications / Programs
/share/apps
Analysis-specific applications are in /share/apps, such as Matlab, FSL, ANTs, etc. If you're looking for something, look here first. Default paths are setup already in your ~/.bash_profile file. If there's something else you need in there let me know. If it's commonly used I'll prioritize its installation.
Edit your settings in your ~/.bash_profile file to choose different versions of the apps as defaults if they're installed. Note that this is different than the old cluster, on which we mainly used .bashrc.
Common linux apps
Common linux apps like gedit are installed in their default location, ususally /usr/sbin or /usr/bin. They should be in your search path by default.
You can also install usually applications in your /home or /data dir if you need a particular version of something or just want to get something installed faster. Any dependencies will have to be installed in one of your directories too since you can't modify system dirs. Be sure to set your search paths appropriately.
Data & Home Directories
Data is in /data. At this point there's:
/data/jet - this is "/jet" from the old cluster /data/jag /data/picsl - the /home data dirs from the old picsl cluster /data/tesla-data - data directories from tesla on the old picsl cluster /data/tesla-home - home dirs from tesla
New users get their data directories in /data/jag by default. As new storage devices get added, they will also appear under /data to help keep things organized.
Your /home directory is for small files only. There are small quotas on /home dirs. Use your data directory for all data and large downloads.
Backup
All data directories are backed up to tape on a quarterly basis and tapes are stored off-site. Users are responsible for maintaining their own copies of original data in the event of catastrophic failure of the system.
Home directories are backed up nightly to another location in the data center, but not archived. Only the most recent contents of your home directory are backed up.
Jobs Can Be Submitted from Nodes
All qlogin sessions must be started from chead.
qsub jobs can be submitted from chead, qlogin sessions or qsub jobs.
If you get an error like this:
denied: host "compute-0-6.local" is no submit host
tell the admins.